| 1. 왜 성능 튜닝을 해야 하는가? |
응답 속도가 느린 웹 사이트는 고객들의 불만이 쌓이고 결국에는 다른 웹 사이트로 이동해 버리게 됩니다. 수익을 목적으로 하는 웹 사이트를 운영하는 기업이라면 고객의 관심뿐만 아니라 비즈니스 기회도 잃어버릴 수 있습니다. 고객이 어쩔 수 없이 성능이 낮은 애플리케이션을 계속 사용해야 한다면 결국에는 비즈니스 트랜잭션이 줄어버리거나, 서비스 사용을 포기하고 떠나가 버릴지도 모릅니다.
기업에서 임직원이 사용하는 애플리케이션이라도 예기치 못한 대기 시간이 발생하거나, 낮은 성능은 기업의 생산성에 영향을 미치게 됩니다. 이러한 상황에서 사용자는 시스템에 대한 불만이 생기고, 업무 시간을 낭비하게 되어 IT부서에 대해서 부정적인 인식이 생기게 됩니다.
성능이 높은 애플리케이션의 특징은 하드웨어나 소프트웨어 자원을 보다 효율적으로 사용하는 것입니다. 튜닝을 통해 최적화된 애플리케이션은 노후화된 시스템을 더욱 오랫동안 사용할 수 있게 되며, 신규 시스템의 경우에는 도입 규모를 축소하더라도 기대한 성능을 제공하여 더 적은 투자비용으로 운영할 수 있습니다.
기업은 튜닝을 통하여 하드웨어 투자를 최적화할 수 있습니다. 소프트웨어 측면에서 보더라도 애플리케이션이 잘 튜닝되어 성능이 좋으면 더 작은 수의 CPU를 사용하게 되고, 이에 따라 소프트웨어 라이선스 비용도 절감할 수 있습니다. 튜닝의 효과로 인해 기업은 시스템을 구축/운영/유지보수 하는 전 단계를 거쳐 비용을 절감하게 됩니다.
(1) 성능 튜닝 목표
성능에 대한 튜닝을 어느 수준까지 할지를 결정하는 것은 어려운 문제입니다. 시스템 운영 초기의 성능은 주로 애플리케이션의 성능 최적화에 크게 의존하며, 이후에는 하드웨어, 데이터베이스, 애플리케이션 서버의 성능에 의해 결정됩니다. 많은 경험을 가진 엔지니어라 하더라도 하드웨어 사양이나 애플리케이션 서버의 종류에 따라 예상되는 성능을 추측하는 것은 불가능합니다. 시스템 성능을 예측하기 위한 가장 현실적인 방법은 부하테스트를 진행하여 주어진 애플리케이션, 하드웨어, 소프트웨어에서 최적화된 성능 기준을 확인하고 이를 바탕으로 추론하는 것입니다.
튜닝된 시스템을 대상으로 부하를 발생시키면 애플리케이션 서버의 부하가 가장 높아집니다. 만약 애플리케이션 서버의 CPU 사용률이 80%가 넘을 경우, 미들웨어 측면에서 리소스에 의한 병목이 없어서 해당 하드웨어와 애플리케이션 서버에서 성능의 한계값에 가깝다고 할 수 있습니다.
성능 튜닝은 병목 구간을 발견하고 이에 대해 대처하는 수준 높은 기술을 요구합니다. 튜닝 작업은 애플리케이션 서버 공급 업체 컨설팅 또는 경험이 풍부한 엔지니어를 찾는 등 외부와 내부의 지식을 효율적으로 사용하여 수행하는 것을 권장합니다.
(2) 성능 튜닝의 기본 원칙
많은 기업의 IT 업계에서 일반적으로 사용하는 성능 벤치마크를 기준으로 미들웨어를 선택합니다. 제품 공급 벤더에서 벤치마크는 판매를 위한 좋은 기준이 되지만 벤치마크 애플리케이션은 일반적인 기업의 운영 환경 애플리케이션과는 달라서 고객에게 잘못된 정보를 전달하는 경우가 있습니다.
공식적인 성능 테스트 결과와 그 구성 환경에 대해서 이해하더라도 기업마다 다르게 구축되는 시스템 환경으로 인하여 성능에 대한 지표를 참조할 수 있는 경우는 많지 않습니다. 현명한 판단을 위해서는 벤치마크 결과 전체를 받아들이기 보다는 거기서 사용된 소프트웨어와 하드웨어의 구성, 서버와 네트워크의 구성, 각종 설정 상태, 애플리케이션 아키텍처를 조사하고 그것을 기업의 애플리케이션 환경과 비교하는 것이 중요합니다.
① 원칙1 : 현재 운영 시스템의 성능을 파악합니다.
성능 튜닝의 첫 번째 단계는 현재 운영 중인 시스템의 상황과 성능을 정확하게 객관적인 수치로 파악하는 것입니다. 만약 운영 중인 시스템을 대체하는 경우라면 운영자들은 그 동안 여러 가지 운영 경험이 있을 것입니다. 접속 사용자 수, 1일 트랜잭션 수, 1주/1달/1년 주기의 트랜잭션 수, 부하의 종류나 변화 등의 지표를 이미 알고 있을 것입니다.
이전 시스템이 어떻게 운영되는지를 더 깊게 이해하면 더 뛰어난 성능 튜닝 결과를 이끌어 낼 수 있습니다.
② 원칙2 : 성능 기준은 평균이 아닌 피크 시간으로 합니다.
성능 요건을 분석할 때는 피크 시간의 부하에 주의를 기울이면서 애플리케이션을 프로파일링하는 것이 중요합니다. 일반적인 비즈니스 애플리케이션의 경우 피크 시간은 출근 직후나 점심식사 시간 이후 오전과 오후에 발생합니다. 애플리케이션에 따라 월말이나 마지막 분기 말마다 피크가 발생하는 경우도 있습니다. 운영자나 개발자 모두 피크 시간의부하 상황에 대해서 항상 주의를 기울여야 합니다.
개발자들이 많이 하는 성능과 관련된 오해 중 하나는 하루의 평균 워크로드를 기준으로 삼는 것입니다. 평균값을 기초로 개발된 애플리케이션은 피크 시의 부하에 충분히 대응할 수 있는 성능을 제공할 수 없습니다.
③ 원칙 3 : 성능은 항상 모니터링해야 합니다.
모든 애플리케이션은 성능을 분석하기 위한 정ㅂ를 제공하고 있습니다. 고객의 사용 패턴이나 부하는 시간에 따라 변화하여 아무리 성능이 뛰어난 애플리케이션이라도 상황에 따라서 좋은 성능을 보장하기 어렵습니다. 애플리케이션 성능이 측정되지 않는 상황에서 장애가 발생하면 그 원인을 밝히는 것은 더욱 어렵습니다.
애플리케이션을 모니터링하면 사전에 비즈니스 상태의 변화를 감지하여 문제가 발생하기 전에 시스템 운영 환경을 그것에 맞게 구성하는 것이 가능합니다.
성능에 관련된 지표들을 어느 정도 수준으로 모니터링할지를 결정하는 것은 튜닝에 대한 전문지식과 시간 그리고 목적에 따라 결정해야 합니다.
④ 원칙 4 : 병목 구간을 파악합니다.
애플리케이션을 모니터링하는 큰 이유 중에 하나는 처리 시간이 많이 소모되는 병목 구간을 찾아내는 것입니다. 시스템을 구성하는 전체 스택 중 각각의 계층별로 걸리는 시간을 파악하고 싶다고 해도 애플리케이션 서버에 포함된 도구들은 애플리케이션 서버의 일부 정보만을 제공합니다.
만약 애플리케이션이 사용자 응답시간 대부분을 데이터베이스에서 소비한다면, 문제의 원인을 밝혀내기 위해서는 데이터베이스가 제공하는 통계 정보를 살펴봐야 합니다.
애플리케이션에서 어느 구간에 시간이 많이 소요되는지를 객관적으로 파악하는 것이 성능 문제를 해결하기 위한 지름길입니다.
⑤ 원칙 5 : 운영 환경과 같은 환경을 구성합니다.
운영 환경에서 시스템이 어느 정도 성능이 제공되는지 정확하게 파악하기 위해서는 테스트 환경에서 성능을 확인해 봐야 합니다. 기업에 따라서는 운영 환경과 동일한 테스트 환경을 갖추는 것을 표준으로 하는 곳도 있습니다. 대규모 시스템을 운영하는 환경에서 애플리케이션이 어떻게 확장해 나가는지를 여러 가지 관점에서 살펴볼 수 있는 환경을 구성해 놓는 것이 시상적인 방법입니다.
그러나 기업에서 운영 환경과 동일하게 갖추기 위해서 비용이 많이 들기 때문에 테스트 환경은 소규모로 구성합니다. 테스트 환경에서 성능과 운영 환경에서 성능의 관련성을 찾기 위한 모델이 필요합니다. 이것이 시스템을 확장하는 데 필요한 모델입니다.
(3) 성능 병목 구간 찾기
성능 튜닝은 우선 병목 구간을 찾는 것부터 시작합니다. 병목 구간을 찾은 후 어떤 상황에서 성능이 감소하는지를 파악하는 것이 중요합니다. 시스템의 성능 분석은 부하테스트와 애플리케이션 프로파일링을 동시에 수행합니다.
① 프로토타입 단계에서 성능이 나오지 않는 경우
아키텍처 설계 단계에서 프로토타입을 만들고 성능 테스트를 하였을 때 성능이 나오지 않는 경우가 있습니다. 성능상의 문제점을 사전에 파악하는 것이 프로토타입의 목적이기도 합니다. 이 단계에서는 성능분석 작업에 아키텍처 설계자와 프로토타입 개발자(한 사람이 두 가지 역할을 하는 경우도 있습니다)가 참여하고 있기 때문에 문제점이 발견되면 그것을 수정하는데 많은 시간이 걸리지 않습니다. 또한, 프로그램 규모가 작아서 프로파일도 효과적으로 진행할 수 있습니다.
② 종합 테스트 단계에서 성능이 나오지 않는 경우
종합 테스트 단계에서 기대한 성능에 도달하지 못한 경우에는 테스트를 진행하여 초기 단계에서 성능에 문제를 발견한 것에 비해 범위는 넓어지지만, 기능별로 성능상의 문제가 되는 것을 비교적 쉽게 찾을 수 있습니다. 이시점ㅁ에서는 아직 서버 설정 변경을 자유롭게 할 수 있으므로 불필요한 요소를 제거하면서 테스트를 수행할 수 있습니다.
③ 운영 중인 시스템에서 성능 문제가 되는 경우
운영 중인 시스템에서 사용자가 "응답 속도가 느리다." 등의 불만이 있을 경우가 있습니다. 먼저 시스템의 어떤 계층에 문제가 있는지를 분명히 해 두지 않으면 시간을 낭비하게 될 수 있습니다. 예를 들어 과부하 시 전체적으로 응답이 나빠지는 것과 같은 막연한 상황에서는 운영 환경의 여러 계층을 의심해야 합니다.
평상 시에 주의 깊게 살펴봐야 할 모니터링 매트릭스를 지정하여 문제가 발생할 때 즉시 대응할 수있도록 운영 환경에서 모니터링을 합니다.
(4) 성능 튜닝 개요
- 하드웨어 / 네트워크
- 운영체제
- Java VM
- 애플리케이션 서버
- J2EE 서비스
- 애플리케이션
전체 시스템의 성능을 높이기 위해서는 각 계층의 튜닝 포인트를 잘 이해하고 개발 단계의 초기 단계에서부터 성능 데이터를 수집하는 것이 중요합니다.

(5) 부하 테스트 및 프로파일링
부하가 낮은 상태에서는 성능이 느려지는 경우가 없기 때문에 부하테스트 도구를 사용하여 부하가 높은 상태에서 병목 구간을 찾을 수 있습니다.
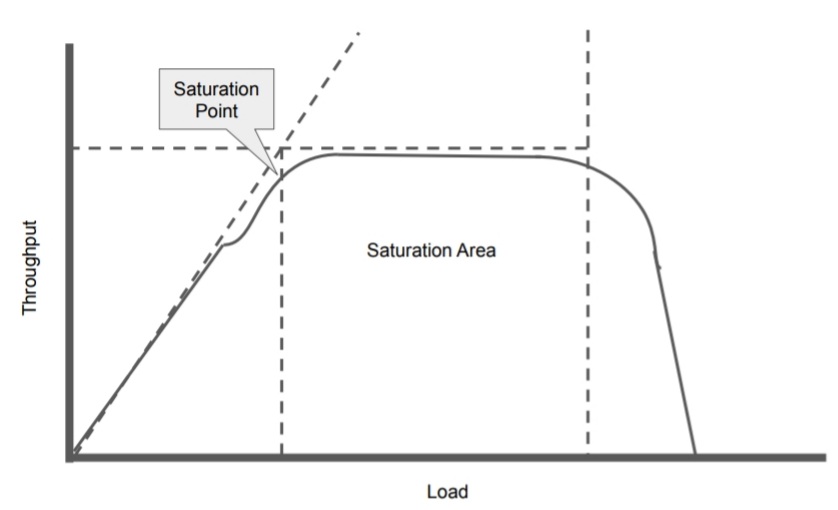
일반적으로 시스템의 성능은 응답 시간과 처리량의 두 가지 측면으로 나타낼 수 있습니다. 클라이언트 수(병렬 처리 요청 수)가 많아지면 처리량은 증가하지만, 응답 시간은 반대로 감소합니다. 클라이언트 수의 증가에 따라 특정 시점을 경계로 처리량 증가가 멈추고(또는 반대로 감소), 응답 시간이 급격히 감소하게 됩니다. 이렇게 처리량이 멈추는 시점을 Saturation 포인트라고 합니다. 먼저 부하 테스트를 통해서 Saturation 포인트를 찾고, 이 한계점보다 앞의 중간 부하 수준(동시 접속 수)에서 합니다.
여러 공급 업체에서 부하 테스트 도구를 제공하고 있지만, 오픈 소스 부하테스트 도구인 Apache JMeter(http://jmeter.apache.org)를 이용하면 상용 도구에 비하면 기능이 적지만 튜닝의 효과를 확인하는 수준이라면 이것으로 충분합니다.
병목이 걸리는 특정 코드는 Java 프로파일링 도구(프로파일러)를 사용하면 됩니다. 프로파일링 도구를 사용하지 못하는 환경이라면, Java의 스레드 덤프를 이용하여 분석할 수 있습니다. 스레드 덤프는 'kill -3 <pid>'를 실행하면 현재 실행 중인 스레드들의 스택 트레이스를 stdout에 출력합니다. 마치 JVM에 대해 X-Ray 사진을 찍는 것과 같습니다. 스레드가 변화하는 상태를 확인하려면 스레드 덤프를 여러 번 연속해서 얻는 것이 좋습니다. 예를 들어 3초 간격으로 5~10회 얻어 분석 합니다.
| 2. OS 튜닝 |
OS에 따라 설정 방법은 다르지만 다음과 같은 유형의 구성에 주목하고 부족한 것이 있으면 설정 값을 늘립니다.
- 라지 페이지 메모리
- 오픈 가능한 파일 수
- 프로세스 수 / 스레드 수
- 데이터 세그먼트 크기 / 스택 크기
- TCP / IP 파라미터
(1) Linux의 Large Page Memory 조정
옛날의 메인 프레임에서부터 지금까지 OS의 메모리 페이지 사이즈는 4KB입니다.이전 4KB 단위는 메인 프레임 아키텍처에서 Magic number이며, 메인 프레임 시스템 전체가 바로 4KB로 튜닝되었습니다. 예를 들면 I/O 명령의 처리 단위는 4KB이고, 디스크 장치의 블록 사이즈도 4KB가 최적 값입니다. 키보드를 입력하면 전송되는 데이터와 응답 화면에 표시되는 데이터 양도 4KB 이하였습니다. 즉, 모든 I/O 처리나 메모리 처리를 4KB 단위 이기 때문에 4KB로 처리하면 최고의 성능을 얻을 수 있는 구조였습니다.
하지만 세월이 흘러 IT 환경이 변화하면서 데이터 크기가 점점 커지게 되고, 메모리 가격도 저렴해짐에 따라 현재 4KB의 페이지 크기는 적합하지 않게 되었습니다. 수십 GB에서 몇 TB의 메모리를 탑재하는 서버도 4KB 단위로 가상 메모리를 관리하면, 페이지 테이블 크기가 커져서 메모리에 부담을 줄 뿐만 아니라 페이징 등의 처리에서 오버헤드가 발생합니다.
최근에 64비트 시스템에서는 라지 메모리 페이지만 사용해도 높은 성능 향상을 기대할 수 있습니다. 기본적인 페이지 사이즈는 4KB입니다. 만약 이 상태로 대용량의 메모리를 사용하게 될 경우 메모리 어드레싱 횟수가 많이 증가합니다. 예들 들면 1기가(1,048,756 Kbyte)라고 하더라고 262,144개의 메모리 페이지가 필요하며 이것은 시스템에 큰 오버헤드가 발생합니다.
리눅스에서는 빈번하게 발생하는 메모리 페이지 맵핑의오버헤드를줄이기위하여 라지 메모리 페이지는 디스크에 스왑핑하지 않습니다.
힙 영역에 대하여 디스크에 스왑을 하게 되면 애플리케이션 성능에 큰 영향을 미치기 때문에 라지 메모리 페이지는 성능에 매우 중요한 요소가 됩니다.
라지 페이지 메모리 크기는 하드웨어에 따라 다르겠지만2MB ~ 256MB입니다. 이 값은 서버 환경에 따라 달라서 사용하고 있느느 서버 환경에 적합한 값을 찾아서 적용해야 합니다.
대부분 Java 가상 머신들은 리눅스에서 라지 메모리 페이지를 지원하고 있습니다. 이 값의 설정은 쉽지 않기 때문에 전문가와 논의하여 진행해야 합니다.
라지 페이지 메모리 즉, Huge Page를 설정하게 되면 리눅스상에서 다른 일반 애플리케이션에서는 사용할 수 없게 되고 지정된 애플리케이션에서만 사용하게 됩니다.
이 메모리는 특정 애플리케이션에 할당되어 있기 때문에 다른 애플리케이션들은 메모리가 제거된 것처럼 보이게 됩니다.
① 라지 페이지메모리 설정 방법
- JVM에 Large Page 메모리 적용
Sun JVM과 Open JDK에서 Large-Page를 사용하려면 다음과 같은 옵션이 필요합니다.
-XX:+UseLargePages
- 커널 파라미터 설정
/etc/sysctl.conf 파일에 아래의 3개의 커널 파라미터를 추가합니다.
- kernel.shmmax = n
n값은 시스템에서 허용되는 공유 메모리 세그먼트의 최대 바이트 값이 됩니다. 사용하고 싶은 최대 JVM heap 사이즈값이 필요합니다. 또는 시스템의 총 메모리 용량을 설정할 수 도 있습니다.
- vm.nr_hugepages = n
n값은 Large-Page의 값입니다. Large-Page의사이즈는 /proc/meminfo를 참조합니다.
- vm.huge_tlb_shm_group = gid
gid는 Large-Page에 접근할 수 있는 그룹ID입니다. 이 설정으로 라지 메모리 세그먼트 접근을 제한할 수 있습니다.
- limits.conf 파라미터 설정
'/etc/security/limits.conf' 파일에 memlock의 제한값을 설정합니다.
<username> soft memlock n
<username> hard memlock n<username>은 JVM 사용자 계정이며, nvm.nr_hugepages의 페이지값과 /proc/meminfo에 KB로 기재되어 있는 페이지 사이즈를 곱한 값을 설정합니다.
- 설정 적용
# sysctl -p
- 리부팅
OS에 메모리 페이지를 할당한 후 안전한 시스템 운영을 위하여 시스템을 리부팅합니다.
- 적용 값 확인
Large-Page가 할당되었다면 /proc/meminfo로 HugePages_Total에 '0'이 아닌 숮가가 표시되게 됩니다. '0'으로 표시되어 있다면 Large-Page는 사용되지 않은 것으로 구성에 문제가 있는 것입니다.
② 라지 메모리 페이지 설정 예
서버에 8GB 메모리를 탑재하고 있다고 가정합니다. JBoss EAP 6의 JVM과 MySQL 데이터베이스가 공유할 수 있도록 6GB를 할당합니다.
- Hugepagesize 확인
'/proc/meminfo'에 있는 페이지 사이즈는 2MB입니다(Hugepagesize: 2049 KB).
# cat /proc/meminfo
... 생략 ...
HugePages_Total: 0
HugePages_free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kb
DirectMap4k: 685952 kb
DirectMap2M: 16082944 kb
- /etc/sysctl.conf 설정
- 최대 공유 메모리 세그먼트 사이즈를 8GB로 변경
kernel.shmmax = 8589934592
- 사용자 계정에서 접근할 수 있도록, hugetlb_shm_group에 gid를 설정
vm.hugetlb_shm_group = 501
- JVM과 MySQL로 공유할 수 있도록 @MB 페이지를 3072개 사용하여 6GB 할당
vm.nr_hugepages = 3072
kernel.shmmax = 8589934592
vm.hugetlb_shm_group = 501
- 계산식
1024 X 1024 X 1024 X 8 = 8589934592
(1024 X 1024 X 1024 X 6) / (1024 X 1024 X 2) = 3072 Pages
- /etc/security/limits.conf 설정
- JVM과 MySQL이 Large-Page 메모리에 액세스할 수 있도록 memlock에 제한값 추가
jboss soft memlock 6291456
jboss hard memlock 6291456
mysql soft memlock 6291456
mysql hard memlock 6291456
root soft memlock 6291456
root hard memlock 6291456
- 계산식
2048KB는 페이지 사이즈 3072 Page X 2048 KB = 6291456
- /etc/group 설정
사용자 계정에 공유 메모리 세그먼트 접근 권한을 주려면 '/etc/group/의 501(hugetlb) 그룹에 JBoss와 MySQL을 추가합니다. 여기서 501은 vm.hugetlb_shm_group에 지정한 값으로 시스템 환경에 맞게 변경합니다.
... 생략 ...
hugetlb:x:501:jboss,mysql
(2) 리눅스에서 가상 메모리 매니저 튜닝
Linux에서 가상 메모리 매니저 튜닝도 가능합니다. 간단히 설정을 변경하여 성능을 향상할 수 있습니다.
Linux 2.6 커널의 swappiness라는 새로운 커널 파라미터가 추가되어 관리자가 Linux 스왑 처리 조정이 가능합니다. 이 파라미터는 0 ~ 100 사이의 값을 설정하지만 값이 클수록 페이지 스와핑을 많이하고, 작으면 많은 메모리가 애플리케이션에 확보된다는 것입니다. 메모리 스와핑이 너무 많이 발생하면 시스템 성능이 낮아지게 됩니다.
/etc/sysctl.conf에 vm.swappiness의 값을 1로 설정하면 애플리케이션이 디스크에 스와핑하는 것을 막을 수가 있습니다.
애플리케이션 서버나 데이터베이스 서버와 같이 높은 성능을 요구하느느 시스템에서 자주 스와핑이 발생하지 않도록 하는 것이 좋습니다. 스와핑이 발생하는 것을 최소화하기 위해 값을 0 ~ 10 정도의 값 사용을 권장합니다. vm.swappiness 값을 0으로 하면 실제 메모리를 다 사용할 때까지 스와핑하지 않게 됩니다.
① vm.swappiness 설정
- swappiness 값을 확인(기본값 60)
cat /proc/sys/vm/swappiness
60
- vm.swappiness 설정 변경
# vim /etc/sysctl.conf
... 생략 ...
vm.swappiness = 10
... 생략 ...
또는
# sysctl -w vm.swappiness=10
- 설정값 반영
# sysctl -p
vm.swappiness의 기본값은 60인데 기본값의 절반인 10~15 정도로 줄이는 것이 스왑 사용량을 더 줄일 수 있습니다. 0으로 설정할 경우 스와핑하지 않기 때문에 어떤 상황에서는 메모리 부족이 빨리 발생할 수 있고 심하면 시스템이 멈추는 현상이 발생할 수도 있스빈다.
이처럼 튜닝할 경우 트레이드 오프가 있기 때문에 이런 튜닝 값들은 테스트를 통해 최적 값을 찾아야 합니다. swappiness값을 줄일 때 주의할 점은 메모리가 부족한 상황이 발생하였을 때 시스템이 가용 메묄 확보를 위해 스와핑하지 않기 때문에 시스템이 느려질 수도 있습니다.
| 3. Apache HTTPD 튜닝 |
(1) Apache Httpd MPM 모듈
아파치 웹 서버는 다양한 환경과 플랫폼에서 동작할 수 있도록 강력하고 유연하게 설계되었습니다. 아파치는 모듈화된 설계로 다양한 환경에 적응해 왔고, 관리자는 환경에 적합하게 컴파일이나 실행 시 어떤 모듈을 로딩할지 선택하여 서버가 제공하는 기능을 결정할 수 있습니다.
Apache Httpd 2.0은 이러한 모듈화된 설계를 웹 서버의 가장 기본적인 부분까지 확장하였습니다. HTTPD 서버는 자식 프로세스에 분배하는 다중처리 모듈(Multi-Processing Modules, MPM)을 통해 시스템의 네트워크 포트에 연결하고, 요청을 받아들이며 받아들인 요청을 처리하는 방법을 선택할 수 있습니다.
MPM은 Apache Httpd 2.0 서버에서 요청을 처리하는 부분입니다. Apache 웹 서버의 MPM은 4가지 종류가 있습니다.
- prefork
- worker
- prechild
- winnt
다음은 리눅스 환경에서 Apache HTTPD의 MPM을 확인하는 방법입니다.
# cd $HTTPD_HOME/SBIN/
# ./httpd -l
Compiled in modules:
core.c
prefork.c
http_core.c
mod_so.c
(2) Prefork MPM과 Worker MPM의 비교
Apache HTTPD 2.0 버전에 추가된 MPM 중 가장 많이 사용하는 Prefork MPM과 Worker MPM의 차이점을 간단하게 설명합니다.
먼저 prefork MPM은 Apache 1.3 버전에서 사용하던 방식으로 자식 프로세스를 먼저 시작해 놓고, 클라이언트 요청에 대해서 각각의 자식 프로세스가 통신을 담당하는 방식입니다. 따라서 자식 프로세스가 어떤 원인으로 정지하더라도 다른 자식 프로세스에 영향을 주지 않는 특징이 있습니다.
Worker MPM은 자식 프로세스에서 멀티 스레드롤 실행되며, 클라이언트 요청을 스레드가 처리하는 방식입니다. 하나의 프로세스가 멀티 스레드를 이용해 여러 요청을 담당하게 되어 prefork방식과 비교할 때, 시작 시 프로세스 수를 줄일 수 있고, 메모리 사용량이 적으며, 부팅 시간이 빠릅니다.
<Apache HTTPD의 Prefork방식과 Worker 방식의 비교>
| Prefork MPM | Worker MPM |
| 프로세스(멀티 프로세스)를 사용해 요청을 처리 | 멀티 스레드와 멀티 프로세스를 사용해 요청을 처리 |
| r = n | r = n x m |
| PHP를 사용하는 웹 사이트에서 높은 성능이 필요하다면 prefork MPM을 사용 | 스레드는 메모리를 작게 사용하고 프로세스 방식보다 시작 시간이 빠르며 성능이 좋음 |
 |
 |
| <IfModule prefork.c> StartServers 8 MaxClients 256 MinSpareServers 5 MaxSpareServers 20 ServerLimit 256 MaxRequestsPerChild 4000 <IfModule> |
<IfModule worker.c> StartServers 2 MaxClients 150 MinSpareThreads 25 MaxSpareThreads 75 ThreadsPerChild 25 MaxRequestsPerChild 0 </IfModule> |
위의 표에서 보면 StartServers는 Prefork와 Worker 모두 있는 항목이지만 Prefork는 8개이고, Worker는 2개입니다. 이 차이는 프로세스와 스레드의 차이에 의한 것입니다. 위의 설정에서 Prefork는 5에서 20개의 프로세스를 항상 유지합니다. Worker는 25에서 75개의 여유 스레드를 유지합니다.
반면 Worker는 프로세스의 제한은 명확하게 설정되어 있지 않습니다. 위의 표에서 Worker는 시작 시 2개 프로세스에서 사용 가능한 스레드가 범위에 없는 경우 프로세스를 추가하거나 불필요한 프로세스를 제거합니다. 또한, MaxRequestsPerChild 0으로 무제한으로 설정되어 있습니다. 서버는 요청을 기다리고 있는 서버 스레드 개수를 체크하여 MaxSpareThreads, 즉 85개 이상이 있으면 서버 프로세스를 제거하고, MinSpareThreads 25개 미만인 경우 새로운 프로세스를 생성합니다.
① Apache HTTPD MPM 주요 설정
Prefork와 worker에서 사용하는 속성들은 아래와 같습니다.
| 속성 | 설명 | 비고 |
| StartServers | Apache HTTPD 시작 시에 생성하는 프로세스 수를 지정합니다. 여기서 지정한 프로세스 수는 시작 시에만 의미가 있으며, Prefork의 경우 시작 이후 프로세스 수는 MinSpareServers와 MaxSpareServers 지정 값에 따라 조정됩니다. |
|
| MinSpareServers | 클라이언트 요청을 기다리는 httpd 서버 프로세스(idle 상태)의 최소값을 지정합니다. 여기에서 지정한 값보다 프로세스 수가 작아지면, 새로운 프로세스를 생성합니다. 트래픽이 많지 않은 사이트의 경우 초기값으로 설정할 것을 권장합니다. | Prefork만 해당 |
| MaxSpareServers | 클라이언트 요청을 기다리는 httpd 서버 프로세스(idle 상태)의 최대값을 지정합니다. 여기에서 지정한 값보다 프로세스 수가 많아지면 프로세스를 제거합니다. 트래픽이 많지 않은 사이트의 경우 초기값으로 설정할 것을 권장합니다. | Prefork만 해당 |
| ServerLimit | Prefork의 경우 서버 프로세스와 클라이언트 수가 같아지기 때문에 MaxClients에 설정한 최대값입니다. Worker의 경우 ThreadLimit와 함께 계산하여 MaxClients에 설정한 최대값입니다. |
Prefork만 해당 |
| MaxClients | 동시에 처리할 수 있는 httpd 서버 프로세스의 수를 지정합니다. 즉, 클라이언트의 최대 접속 수 입니다. Prefork의 경우는 프로세스 수를 지정하고, Worker의 경우는 스레드 수를 지정합니다. | |
| MaxRequestsPerChild | 하나의 httpd 프로세스로 처리할 수 있는 요청의 최대값을 지정합니다. 0은 무제한입니다. |
|
| MinSpareThreads | 클라이언트 요청을 기다리는 스레드(idle 상태)의 최소값을 지정합니다.. Prefork의 MinSpareServers에 해당합니다. |
Worker만 해당 |
| MaxSpareThreads | 클라이언트 요청을 기다리는 스레드(idle 상태)d의 최대값을 지정합니다. Prefork의 MaxSpareServers에 해당합니다. |
Worker만 해당 |
| ThreadsPerChild | Worker 프로세스 내에서 생성하는 스레드 수를 지정합니다. | Worker만 해당 |
(3) Worker MPM으로 전환
Apache HTTPD를 사용할 때 prefork MPM 방식을 적용해서 성능의 문제가 된다면 Worker 방식으로 변경합니다.
Prefork 경우 ServerLimit는 Apache 프로세스의 MaxClients에 설정 가능한 최대값을 설정합니다. 이는 '동시 클라이언트 수(MaxClients) = 최대 서버 프로세스 수(ServerLimit)'가 되며, ServerLimit는 MaxClients 값 이상으로 설정할 필요가 없습니다.
Worker 경우에는 'MaxClients(총 스레드 수) / ThreadsPerChild(ㅎ하나의 프로세스가 생성하는 스레드 수) = 최대 서버 프로세스 수(ServerLimit)'가 됩니다.
ServerLimit = MaxClients / ThreadsPerChild
앞서 설명한 내용들에 대한 이해를 돕기 위해 다음 예를 들어 설명합니다.
<IfModule worker.c>
ServerLimit 60
StartServers 2
MaxClients 1500
MinSpareThreads 25
MscSpareThreads 75
ThreadsPerChild 25
MaxRequestsPerChild 1000
<IfModule>
예제에서는 MaxClients(접속 가능한 요청의 최대값)를 1500으로 할 때, ServerLimit 설정 값은 '1500(MaxClients) / 25(ThreadsPerChild) = 60 프로세스(ServerLimit)'가 되므로 60이 됩니다.
참고 서적 : 거침없이 배우는 JBoss
'IT 이야기 > JBoss EAP' 카테고리의 다른 글
| JBoss EAP 6과 친해지기 24탄 - JBoss EAP 6 운영환경 구축 가이드 (4) | 2021.01.29 |
|---|---|
| JBoss EAP 6과 친해지기 23탄 - JBoss EAP 6 튜닝 #2 (0) | 2021.01.21 |
| JBoss EAP 6과 친해지기 22탄 - JBoss EAP 6 모니터링 #2 (0) | 2021.01.11 |
| JBoss EAP 6과 친해지기 22탄 - JBoss EAP 6 모니터링 #1 (0) | 2021.01.11 |
| JBoss EAP 6과 친해지기 21탄 - 애플리케이션 배포 (0) | 2021.01.11 |




댓글