| 4. JVM 튜닝 |
(1) 개요
Java 언어에서 오브젝트에 대한 메모리 할당과 해제는 Java 가상 머신이 자등으로 관리합니다. 메모리에서 사용된 오브젝트를 자동으로 제거하는 메커니즘을 '가비지 컬렉션'이라 합닏.ㅏ 가비지 컬렉션은 Java 프로그램 성능에 결정적인 영향을 주기 때문에 그 동작 방법을 이해하고, 튜닝하는 것은 매우 중요합니다.
(2) 가비지 컬렉션 역할
Java 언어에서는 생성된 오브젝트를 메모리에 할당하기 위해 코드에서 명시적으로 메모리 공간을 확보하거나 제거할 필요가 없습니다. 이것은 C나 C++ 등의 언어와 Java 언어를 비교했을 때 까장 큰 차이점 중의 하나입니다. C나 C++에서는 명시적으로 프로그램이 사용하는 메모리 영역을 할당하고, 사용한 영역을 해제하도록 프로그램 코드로 작성해야 합니다.
Java 가상 머신은 실행되고 있는 Java 프로그램 내에서 어디에도 참조되지 않는 불필요한 Java 오브젝트를 찾아 해당 영역의 메모리를 자동으로 해제합니다. 이렇게 Java 오브젝트를 자동으로 제거하는 방법을 '가비지 컬렉션'이라고 합니다. Java 가상 머신 내부에서 가비지 컬렉션은 별도의 스레드로 주기적으로 동작합니다. 이 가비지 컬렉션이 동작하는 주기는 Java 가상머신 힙의 크기와 애플리케이션에서 힙 메모리를 어떻게 사용하는지에 따라 달라집니다.
Java 애플리케이션이 실행되면 오브젝트는 메모리에 로드됩니다. 사이즈가 큰 객체를 사용하거나 사용하는 오브젝트 개수가 많으면 그만큼 메모리 사용량이 증가합니다. Java에서 사용 가능한 메모리 영역을 힙 영역이라고 합니다. 힙 영역 이외에도 Permanent 영역이 있습니다. 새롭게 생성된 오브젝트들을 계속 로드하면 Java가 사용할 수 있는 메모리 공간이 가득 차게 됩니다.
메모리가 가득 차면 새 객체를 로드할 수 없어서 프로그램을 실행할 수 없습니다. 그래서 이를 방지하기 위한 구조가 가비지 컬렉션, GC(Garbage Collection)입니다. GC는 힙에 여유가 없을 때 사용되는 객체와 사용되지 않는 객체를 판별하여 사용되지 않는 객체를 청소 대상으로 하여 메모리에서 삭제하는 방법으로 메모리 공간을 확보합니다.
Java 프로그래머들이 GC와 같은 JVM의 내부 작동 방법에 관해서 관심을 기울이지 않을 수도 있습니다. 하지만 신뢰성이 높고 성능이 좋은 Java 시스템을 구축하기 위해서는 JVM 내부 메모리 관리 기능인 GC에 대해 그 구조를 파악하는 것이 매우 중요합니다. 메모리 관련(OufOfMemoryError 등) 장애가 발생하였을 때 신속하게 파악하고, 조치하기 위해서는 GC에 대한 지식은 도움이 됩니다.
(3) 가비지 컬렉션 장점
C나 C++ 언어에서 프로그래머가 객체에 할당된 메모리 영역이 불필요하게 되면 프로그래머가 책임을 지고 해당 오브젝트가 사용한 메모리를 명시적으로 해제해야 합니다. 만약 개발자가 이를 잊고 해제하지 않은 경우 메모리 누수와 잘못된 메모리 해제로 인하여 애플리케이션이 크래시 되어 장애의 원인이 됩니다.
이런 메모리 문제로 인한 버그는 잘못된 프로그램 코드와 실제 문제가 발생한 부분이 달라서 재현과 디버깅이 매우 어렵습니다. 장시간 동안 안정되게 운영해야 하는 웹 애플리케이션 서버에서는 큰 문제가 될 수 있습니다.
Java 런타임 환경에서는 메모리 공간을 확보하기 위해 프로그래머가 명시적으로 메모리 해제에 대해 신경 쓸 필요가 없습니다. 메모리 해제에 대한 개발자가실수가 없어서 신뢰성, 안정성이 높은 애플리케이션 개발을 할 수 있습니다. 물론 JKava에서도 잘못된 코딩으로 메모리 누수가 발생하는 경우가 있습니다.
가비지 컬렉션으로 메모리 관리의 장점이 있지만, 반면 이 때문에 애플리케이션의 성능이 감소하고, 응답 시간이 지연되는 등 성능 병목 현상의 원인이 될 수 있습니다.
특히 메모리가 크고, 많은 CPU를 사용하는 대규모 시스템에서는 가비지 컬렉션으로 인한 성능 저하도 비례하여 증가하게 됩니다. 가비지 컬렉션이 큰 메모리 영역을 여러 CPU로 효율적으로 처리하는 것이 과제입니다. 이것을 해결하기 위해서는 가비지 컬렉션 작업을 여러 스레드로 동시에 진행하는 병렬 가비지 컬렉션과 애플리케이션 스레드와 가비지 컬렉션 작업을 동시에 하는 Concurrent 가비지 컬렉션 방법 등이 있습니다.
(4) Java 힙 메모리 이해
Java 가상 머신에서 힙 영역은 신세대(Young Generation : New 영역)와 구세대(Tenured Generation 또는 Old Generation : Old 영역) 영역 그리고 영구 세대(Permanent Generation 영역) 영역으로 세대(Generation)라는 개념으로 나누고 각각 다른 알고리즘으로 가비지 컬렉션을 수행합니다.
Java에서 새로운 오브젝트를 생성하면 New 영역에 저장되고, 자주 참조되는 오래된 오브젝트들은 Old 영역에 저장됩니다. Permanent 영역에는 클래스나 메소드 등의 정보가 저장됩니다.
가비지 컬렉션은 신세대와 구세대 중 어떤 힙 영역을 대상으로 하느냐에 따라 다음 두 가지 종류가 있습니다. 첫 번째로 'Scavenge(Minor) GC'는 신세대(Young / New Generation) 공간이 부족하면 실행되며, 비교적 자주 발생하고 짧은 시간에 처리가 끝납니다. 두 번째로 'Full GC'는 Old 영역과 Permanent 영역이 부족하면 실행되며 비교적 부하가 많은 작업이기 때문에 처리 시간이 오래 걸립니다.
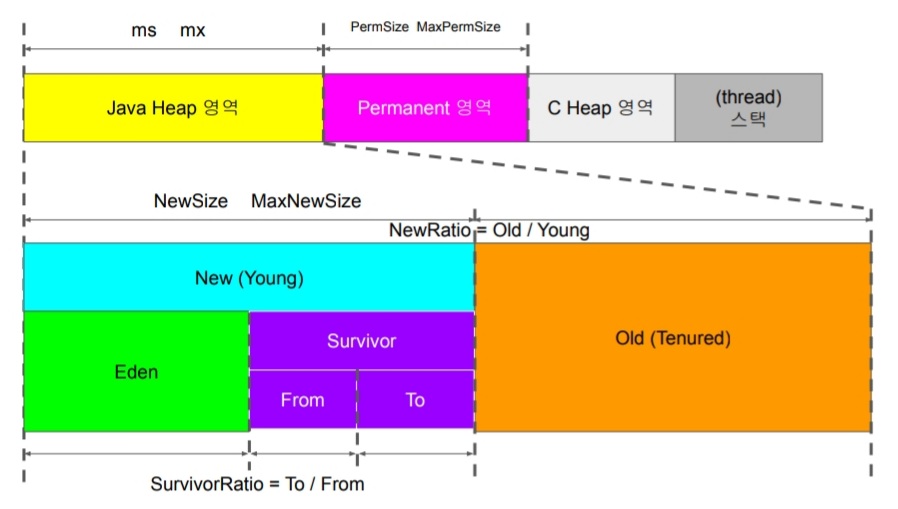
① New 영역(Young Generation)
New 영역은 Eden과 Survivor로 나누어지고, Survivor는 다시 From, To로 나누어져 총 세 개의 영역으로 나뉩니다.
프로그램이 실행된 후 새로운 오브젝트는 먼저 Eden 영역에 생성됩니다.
Eden 영역이 새로운 오브젝트들로 가득차게 되면, Scavenge GC(New / Young 영역 GC)에 의해 사용되지 않는 객체는 삭제되고, 사용 중인 객체는 From 영역과 To 영역으로 이동합니다.
Scavenge GC는 번갈아 한번은 Eden 영역과 From 영역에 오브젝트들을 조사하여 사용하지 않은 오브젝트는 삭제합니다. 사용된 오브젝트는 To 영역으로 복사하고, 다음번에 Eden 영역과 To 영역을 조사하여 사용하지 않은 오브젝트는 삭제, 사용된 오브젝트는 From 영역으로 복사합니다.
이런 방법으로 오브젝트들의 From 영역과 To 영역으 이동하는 횟수를 세어 사용 빈도가 높다고 판단된(MaxTenuringThreshold : 기본값은 32회) 오브젝트들을 OLD 영역으로 이동하여 Full GC 전까지 살아남을 수 있습니다. New 영역이 부족하면 Scavenge GC가 자주 발생합니다.
② Old 영역(Tenured Generation 또는 Old Generation)
New 영역에서 살아남은 오브젝트가 저장되는 영역입니다.
즉, 수명이 긴 오브젝트들이 이 영역에 배치됩니다.
Java 가상머신은 Old 영역이 가득 차면 Full GC를 수행합니다.
③ Permanent 영역(Permanent Generation)
클래스나 메소드 정보가 저장되는 영역입니다. 많은 클래스를 로드하거나 JSP를 많이 사용하는 경우 Permanent 영역이 부족할 수 있어 보통 크기를 늘려 사용합니다. Java 가상머신은 Permanent 공간이 부족해도 Full GC를 수행합니다.
힙 영역과 Permanent 영역을 설정하려면 다음과 같이 Java 옵션을 지정합니다. m은 MB입니다.
-Xms1024m -Xmx1024m --XX:NewSize=128m -XX:MaxNewSize=128m -XX:PermSize=64m -XX:MaxPermSize=256m
다음은 힙 영역의 가비지 컬렉션 종류별 대상 영역에 대한 그림입니다.

또한, Full GC가 수행되는 동안 다른 작업을 할 수 없어서 시스템은 정지 상태가 되며 이름 'Stop The World'라고 합니다. Full GC는 시스템 성능에 큰 영향을 주기 때문에 가능한 발생하지 않도록 조정해야 합니다.
다음은 Java 실행 옵션 중 메모리와 관련한 주요 옵션들입니다.
| 항목 | 설명 |
| -Xms : 힙 메모리 초기값 -Xmx : 힙 메모리 최대값 |
-Xmx와 -Xms는 각각 Young 영역과 Old(Tenured) 영역을 더 한 Heap 전체의 초기 메모리와 최대 메모리 크기 입니다. 초기값과 최대값이 다를 경우 힙 메모리의 변환에 따라 조정하는 작업으로 성능이 느려질 수 있습니다. 하드웨어 자원이 충분한 경우 성능 감소를 막기 위해서 초기값과 최대값을 같게 설정합니다. |
| -XX:NewSize : New 영역의 초기값 -XX:MaxNewSize : New 영역의 최대값 |
NewSize와 MaxNewSize는 각각 Young 영역의 초기값과 최대값입니다. 초기값과 최대값이 다를 경우 힙 메모리의 변화에 따라 조정하는 작업으로 성능이 느려질 수 있습니다. Young 영역이 작으면 Scavenge GC가 빈번하게 발생되며 동시에 비교적 수명이 짧은 오브젝트가 Tenured 영역으로 이동하여 Full GC의 빈도도 높아집니다. Young 영역을 크게 잡으면 Scavenge GC 비용이 증가합니다. |
| -XX:PermSize : Permanent 영역 초기값 -XX:MaxPermSize : Permanent 영역 최대값 |
Permanent 영역은 Java 오브젝트의 클래스 정보가 저장되는 영역입니다. 클래스 수는 애플리케이션 로직과 구조에 따라 결정되며 클래스 수가 늘어나면 Permanent 영역의 크기가 증가합니다. 클래스는 동적으로 JVM에서 로드되기 때문에, 애플리케이션의 크기에 따라Permanent 사이즈도 증가합니다. Permanent 영역이 부족하면 Full GC도 자주 일어납니다. JBoss EAP 6에서 배포 스캐너를 적용한 상태에서 JBoss 실행 중에 재배포를 하는 경우, 클래스를 교체해야 해서 Permanent 영역을 충분히 크게 확보해야 합니다. |
| -Xss | 개별 스레드의 스택 사이즈를 지정합니다. 스택을 어느 정도 사용하는지는 애플리케이션 로직에 따라 다릅니다. 예를 들어, 스레드 스택 사이즈가 1M이고, 스레드가 최대 100개 사용된다면 최대 100m의 메모리를 사용하게 됩니다. 많은 수의 스레드를 사용하는 애플리케이션은 스레드 스택 메모리도 많이 사용합니다. 스택 저장 영역이 부족하면 OutOfMemory 또는 프로세스 장애가 발생합니다. |
<Java 애플리케이션에서 'Stop-The-World'>
Java 플랫폼은 가비지 컬렉션으로 인한 치명적인 문제를 내장하고 있습니다. Java 애플리케이션은 Full GC를 수행하는 동안 모든 애플리케이션 스레드가 중지됩니다. 아래의 그림은 Parallel GC를 적용하였을 때 Stop The World가 발생하는 모습입니다.

Stop-The-World는 가비지 컬렉터가 애플리케이션에서 동작 중인 모든 스레드를 멈춘 후 가비지 컬렉션을 수행하는 방식입니다. 이 때문에 정지 시간이 실제로 애플리케이션에 얼마나 영향을 주었는지를 분석하기 위해서는 GC 로그를 확인해야 합니다.
Java에서 가비지 컬렉터로 사용할 수 있는 방식은 다음 표와 같습니다. 해당 옵션에 대한 자세한 정보는 Oracle의 Java 가상 머신에 대한 페이지를 확인하면 됩니다.
| 구분 | 옵션 |
| Serial GC | -XX:+UseSerialGC |
| Parallel GC | -XX:+UseParallelGC -XX:ParallelGCThreads=value |
| Parallel Compacting GC | -XX:+UseParallelOldGC |
| CMS GC | -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=value -XX:+UseCMSInitiatingOccupancyOnly |
| G1 | -XX:+UnlockExperimentalVMOptions -XX:+UseG1GC |
(5) Java 가상 머신 성능 튜닝
시스템 내부에서는 수 많은 구성 요소들이 함께 동작하고, 서로 복잡하게 의존하고 있습니다. 따라서 어떤 부분이 병목인지 찾는 것은 매우 어려운 일입니다.
Java 가상 머신의 성능 튜닝은 웹 시스템 전체의 성능 튜닝 중 일부이며, 제일 마지막 단계의 병목을 찾아내는 부분이라 할 수 있습니다. Java 가상 머신의 튜닝은 OS, 웹 서버, 데이터베이스 서버, 웹 애플리케이션 서버 등의 튜닝에 비하여 노력 대비 얻는 효과가 높지 않지만, 안정된 서비스를 제공해야 하는 측면에서는 매우 중요하며 난이도와 노력이 많이 필요한 부분입니다.
특히 Java 가상 머신의 성능 튜닝은 필요한 모든 데이터를 모니터링하고, 수집하여 분석해서 추측하는 과정을 반복해서 수행해야 하는 과정입니다. 성능 문제를 신속하게 해결하지 않으면 안 되는 긴급한 상황이 많기 때문에 모니터링과 분석 단계에 시간을 주지 않고, 추측이나 가설만 가지고 대응해 버리는 경우가 많습니다. 그러나 이러한 임기응변적인 대응은 상황을 더욱 악화시키게 됩니다. 시급하고 중요할수록 일정한 절차에 따라 성능 튜닝을 실시하는 것이 바람직합니다.
GC 로그, Java 프로파일링, Java 스레드 모니터링, 힙 메모리 등의 도구들은 각각의 용도에 맞게 오픈 소스부터 상용 제품까지 다양한 제품이 있으니, 시스템 운영 상황에 맞는 적절한 분석 도구들을 사용하여 측정 결과를 확인하고, 성능 개선과 안정성 확보를 위한 작업을 지속해서 수행해야 합니다.
| 5. 웹 애플리케이션 서버 튜닝 |
웹 애플리케이션 서버 튜닝에서는 실행 스레드, 기본I/O, JDBC 커넥션 풀링, EJB, 클러스터링 5가지 항목에 대해서 이야기 합니다.
(1) 데이터베이스 커넥션 풀링
새롭게 구축되는 시스템에서 성능을 최대로 발휘하기 위해서 데이터베이스 커넥션 풀과 스레드 풀을 튜닝하는 것은 중요한 부분입니다.
시스템 리소스 관점에서 보면 데이터베이스 커넥션을 열거나 닫는 것은 매우 비용이 많이 드는 작업입니다. 최근에 많지는 않지만 애플리케이션 개발 시 데이터베이스 조회나 트랜잭션에 대해 매번 새로운 커넥션을 생성하고, 바로 닫는 경우도 있습니다. 이러한 방식은 트랜잭션 처리에 큰 오버헤드가 발생하여 성능 감소의 원인이 됩니다. JBoss EAP 6에서 데이터베이스 커넥션 풀 기능을 제공하고 있으니, 이를 이용하는 방법이 성능이나 안정적인 서비스를 위해 권장합니다.
(2) 스레드 튜닝
스레드 풀은 애플리케이션의 성능을 튜닝하는데 있어서 두 번째로 중효한 부분입니다. JBoss EAP 6는 견고한 스레드 풀 기능을 갖추고 있지만, 이를 운영 환경에 적합하게 설정하기 우해서는 각각의 스레드 풀의 용도와 애플리케이션 성능에 미치는 영향을 파악해야 합니다.
애플리케이션 종류에 따라 사용하는 스레드 풀이 다르며 어떤 부분에 병목이 있는지도 다릅니다.
애플리케이션 종류나 사용 방식에 따라 매우 달라서 주의가 필요합니다.
스레드 수가 많다고 무조건 성능이 향상되지는 않습니다. 스레드는 CPU 성능과 관련이 깊어 스레드 수가 성능에 미치는 영향은 다음과 같습니다.
- 스레드 수가 너무 많은 경우 스레드 관리를 위한 오버헤드가 증가해서 반대로 성능이 감소합니다. CPU 사용량이 피크에 도달한 상황에서는 스레드 수를 줄이면 성능이 향상될 수 있습니다.
- 스레드 수가 너무 적은 경우 CPU 사용률이 감소하고 지연 시간이 발생할 수 있습니다. 이 경우 스레드 수를 늘려 성능 향상할 수 있습니다.
최적의 스레드 수는 시스템 구성(특히, CPU 수, CPU 성능)에 따라 각각 다릅니다. 부하 테스트 등으로 스레드 수의 최적값을 찾아야 합니다.
(3) 스레드 튜닝 시 유의점
CUP의 사용량이 100%가 아닐 때 클라이언트의 요청이 자주 블록되거나 거절되는 경우에만 실행 스레드 수를 튜닝합니다.
스레드 수를 튜닝할 때 처리량이 떨어지거나 CPU 사용량이 떨어지거나 일정하게 유지되는 경우에는 튜닝을 중지합니다.
애플리케이션 컴포넌트를 파티셔닝하거나 지정된 수만큼의 자원을 컴포넌트에 할당하기 위해서는 사용자 정의(user-defined)관 큐를 설정합니다.
커스텀 실행 큐를 사용하면 잠재적인 크로스서버 데드락(cross-server deadlock)을 방지할 수 있습니다.
메시지 드리븐 빈(Message-driven Bean)에 지정된 리소스를 할당하기 위해서는 배치된 각각의 메시지 드리븐 EJB마다 개별적인 실행 큐를 사용합니다.
JBoss EAP에서 오랫동안 실행되는 요청이나 데드락의 원인을 찾기 위해서 적당한 간격의 일련의 스레드 덤프(thread dump)를 받아 분석합니다. 에를 들어 3~5초 간격 5회 스레드 덤프를 받아 분석합니다.
(4) 웹 서브시스템
JBoss EAP 6만 사용하여 웹 시스템을 구축할 수 있지만, 일반적으로는 JBoss EAP 6의 앞단에 Apache 웹 서버를 배치해, 정적 컨텐츠(HTML, CSS, 이미지 등의 정적 파일)의 전달이나 로드 밸런싱을 수행합니다. 아파치 웹 서버를 이용하여 로드 밸런싱을 구축하는 경우, mod_jk 또는 mod_cluster 등의 모듈을 사용하여 소프트웨어 로드 밸런스 형태로 사용합니다.
다음 그림은 웹 애플리케이션 서버 시스템의 일반적인 구성입니다. 서버 시스템은 외부에서 HTTP 요청을 받고 HTTP 응답을 반환하는 웹 서버, 웹 서버에서 전달된 요청에 대한 업무를 처리하는 애플리케이션 서버, 업무 처리 결과 데이터를 업데이트 하는 데이터베이스 서버로 구성합니다.

① 동시 접속 수
웹 서브시스템은 HTTP/1.1 커넥터(기본 포트 번호 8080) 및 AJP/1.3 커넥터(기본 포트 번호 8009)를 사용해 앞 단의 웹 서버와 통신합니다. 여기에서는 주로 HTTP 또는 AJP 요청을 처리하는 JBoss EAP 6의 워커 스레드 수를 '동시 접속 수'로 튜닝하는 방법을 소개합니다.
웹 서브시스템은 클라이언트 요청에 대해서 스레드를 할당해 처리합니다. 웹 시스템은 이러한 요청을 처리하기 위해 워커 스레드를 사용하게 되며, 워커 스레드의 생성과 소멸을 효율적으로 처리하기 위해 내부적으로 스레드 풀링을 사용합니다.
웹 서브시스템은 클라이언트의 요청을 수신하면 풀에서 대기 상태의 스레드를 할당하고, 요청이 완료(클라이언트에 응답 완료 시)되면 스레드 풀에 반환합니다. JBoss EAP 6의 앞단에 Apache 웹 서버를 설치한 경우 요청 처리 완료 후에도 Apache와 JBoss EAP 6 간의 연결은 일정 기간 연결된 상태로 남아 있어, 스레드 풀오 반환은 연결이 완전히 끊어진 이후가 됩니다.

요청이 들어왔을 때 스레드 풀의 최대값에 도달하지 않는 경우 새로운 스레드를 생성하여 할당합니다. 스레드 풀이 최대값에 도달한 경우에는 클라이언트와 연결되지 않습니다.
클라이언트의 동시 접속 수는 이 스레드 풀의 최대값에 의해 결정됩니다. 스레드 풀은 커넥터마다 생성하여 관리합니다. 여러 개의 웹 애플리케이션이 배포된 서버에서는 같은 커넥터를 사용해 애플리케이션 간에 스레드 풀을 공유합니다.
스레드 풀의 최대값은 커넥터의 max-connections 속성에 설정합니다. 동시 접속 수는 애플리케이션 서버보다 앞에 설치하는 웹 서버의 최대 동시 접속 수나 웹 서버의 대수를 고려해 값을 계산합니다. max-connections로 설정한 값이 웹 서버의 동시 접속 수 보다 적은 경우, 웹 서브시스템의 워커 스레드가 부족하여 접속 에러가 발생할 수 있어 주의해야 합니다.
- AJP/1.3 커넥터
| 위치 | 속성 | 설명 |
| /subsystem=web/connector=ajp | max-connections | 워커 스레드 풀의 최대값 기본값은 JVM이 사용할 수 있는 CPU 코어 수 x 512 |
- HTTP/1.1 커넥터
| 위치 | 속성 | 설명 |
| /subsystem=web/connector=http | max-connections | 워커 스레드 풀의 최대값 기본값은 JVM이 사용할 수 있는 CPU 코어 수 x 512 |
② 동시 접속 수 튜닝
다음은 CLI를 이용하여 AjP/1.3 커넥터의 max-connections의 값을 2000으로 설정하는 예입니다.
- 웹 서브시스템의 AJP 커넥터의 max-connections 속성을 2000으로 설정
[standalone@localhost:9999 /] cd /subsystem=web/connector=ajp
[standalone@localhost:9999 connector=ajp] :write-attribute(name=max-connections,calue=20000)
{
"outcome" => "success",
"response-headers" => {
"operation-requires-reload" => true,
"process-state" => "reload-required"
}
}
- reload
[standalone@localhost:9999 /] /:reload
{ "outcome" => "success" }
- 웹 서브시스템의 AJP 커넥터의 max-connections 속성 확인
[standalone@localhost:9999 /] cd /subsystem=web/connector=ajp
[standalone@localhost:9999 connector=ajp] :read-attribute(name=max-connections)
{
"outcome" => "success",
"result" => 2000,
"response-headers" => { "process-state" => "reload-required" }
}
- max-connections 산정 방법
max-connections의 값을 결정하는 계산 식은 다음과 같습니다.
| max-connections = (Apache의 MaxClients) x (웹 서버 수) x α * MaxClients는 Apache 웹 서버의 MPM에서 설정한 최대 동시 접속자 수 입니다. * α(가중치) : 일반적으로 1.0을 사용하지만, 스레드 수가 부족하여 에러가 발생한다면 1.5 ~ 2.0 정도로 설정합니다. 다른 JBoss EAP 6 인스턴스가 다운됐을 경우에서도 모든 웹 서버로부터의 요청을 처리할 수 있도록 웹 서버의 대수를 고려해야 합니다. 또한, 스레드의 생성과 소멸은 비동기이기 때문에 가중치의 조정이 필요합니다. |
③ HTTP/AJP 커넥션에 대한 스레드 풀 설정
HTTP/AJP 커넥터에 대한 스레드 풀의 최대값을 충분히 설정해야 합니다.
<connector name="ajp" protocol="AJP/1.3" scheme="http" socket-binding="ajp" executor="http-thread-pool" max-connections="3260"/>
<connector name="http" protocol="HTTP/1.1" scheme="http" socketbinding="http" enable-lookups="false" executor="http-thread-pool" max-connections="3260"/> <subsystem xmlns="urn:jboss:domain:threads:1.1">
... 생략 ...
<unbounded-queue-thread-pool name="http-thread-pool">
<max-threads count="250"/>
<keepalive-time time="60" unit="minutes"/>
</unbounded-queue-thread-pool>
... 생략 ...
</subsystem>
④ 커넥션 타임아웃
로드 밸런스 등의 용도로 mod_jk, mod_proxy, mod_cluster 등의 모듈을 사용하기 위해 Apache를 JBoss EAP 6 앞에 배치했을 경우, Apache 웹 서버와 JBoss EAP 6간의 연결은 일정 시간 연뎔된 상태를 유지할 수 있도록 합니다.
지정한 시간 동안 요청이 없는 경우 타임아웃으로 끊어져 할당되어 있던 워커 스레드는 스레드 풀에 반환합니다.
연결 타임아웃은 시스템 프로퍼티로 지정합니다. AJP 및 HTTP 각각의 커넥터의 connection 타임아웃 지정은 다음과 같은 시스템 프로퍼티를 사용하여 설정합니다.
- AJP/1.3 커넥터
| 커넥터 | 설명 |
| org.apache.coyote.ajp.DEFAULT_CONNECTiON_TIMEOUT | 연결 요청에 대해 응답이 없는 경우 대기 시간을 밀리 세컨드로 지정 기본값은 -1(무제한) 이어서 요청이 없어도 connection은 끊어지지 않음 |
- HTTP/1.1 커넥터
| 커넥터 | 설명 |
| org.apache.coyote.http11.DEFAULT_CONNECTION_TIMEOUT | 연결 요청에 대해 응답이 없는 경우 대기 시간을 밀리 세컨드로 지정 기본값은 60000밀리 세컨드(60초) |
⑤ 커넥션 타임아웃 튜닝
Apache 웹 서버와 JBoss EAP 6 간에 유지되는 연결은 아파치 웹 서버에 대한 타임아웃 설정이 있으며 지정한 시간 동안 응답이 없으면 웹 서버에서 연결이 끊어지게 됩니다.
다음은 시스템 프로퍼티 org.apache.coyote.ajp.DEFAULT_CONNECTION_TIMEOUT값을 60000으로 설정하는 예입니다. 또, mod_jk, mod_cluster(mod_proxy)의 connection 타임아웃 설정의 항목은 다음 표와 같습니다.
| 커넥터 | 타임아웃 속성 | 설명 |
| mod_jk | connection_pool_timeout | JBoss 대기 상태 connection의 타임아웃 시간(초) 지정 |
| mod_cluster (mod_proxy) |
ttl | JBoss와 연결 대기 상태 타임아웃 시간(초) |
⑥ 네이티브 커넥터
JBoss EAP 6는 Pure Java로 만들어진 Java EE 애플리케이션 서버입니다. JBoss Web에서는 성능 향상을 위해 JBoss Web Native라는 C언어로 작성된 네이티브 커넥터를 제공합니다. 네이티브 커넥터는 APR(Apache Portable Runtime)라는 API를 이용하고 있어 APR 커넥터라고도 말합니다. Native 커넥터를 사용하면 HTTP 및 AJP의 요청과 응답 처리가 10% 정도 향상됩니다.
Native 커넥터를 이용하기 위해서는 JBoss EAP 6의 Native 컴포넌트를 Red Hat 고객포털에서 다운로드하여 설치해야 합니다. 사용하는 OS에 해당하는 Native 컴포넌트 ZIP 파일을 다운로드하여 JBoss EAP 6가
설치된 디렉터리에 압축을 풀기만 하면 됩니다.
$ cd $JBOSS_HOME
$ cd ..
$ unzip ~/Downloads/jboss-eap-native-6.2.0-RHEL6-x86_64.zip
설치 후에 '/modules/system/layers/base/org/jboss/as/web/main/lib/linux-x86_64' 디렉터리가 $JBOSS_HOME 디렉터리에 있는지 확인합니다.
mvn [options] [<goal(s)>] [<phase(s)>]$ ls $JBOSS_HOME/modules/system/layers/base/org/jboss/as/web/main/lib/linux-x86_64
libapr-1.so libcrypto.so libssl.so libtcnative-1.so
웹 서브시스템의 네이티브 커넥터를 사용하기 위해서 CLI 모드에서 다음과 같이 실행합니다.
[standalone@localhost:9999 /] /subsystem=web:write-attribute(name=native,value=true)
{
"outcome" => "success",
"response-headers" => {
"operation-requires-reload" => true,
"process-state" => "reload-required"
}
}
네이티브 커넥터가 동작하는지 확인하려면 다음과 같이 AprLifecycleListener Logger를 DEBUG 레벨로 추가하여 확인할 수 있습니다.
[standalone@localhost:9999 /] /subsystem=logging/logger=org.apache.catalina.core.AprLifecycleListener:add(category=org.apache.catalina.core.AprLifecycleListener,level=DEBUG)
{ "outcome" => "success" }
서버 시작 시 server.log 파일에 다음과 같이 네이티브 커넥터를 로딩하는 것이 표시 됩니다.
01:47:22,910 INFO [org.jboss.as.security] (MSC service thread 1-1) JBAS013170: Current PicketBox version=4.0.19.SP2-redhat-1
01:47:22,938 INFO [org.jboss.as.naming] (MSC service thread 1-2) JBAS011802: Starting Naming Service
01:47:23,191 DEBUG [org.apache.catalina.core.AprLifecycleListener] (MSC service thread 1-1) Loaded: apr-1
01:47:23,191 DEBUG [org.apache.catalina.core.AprLifecycleListener] (MSC service thread 1-1) Loaded: z
01:47:23,220 INFO [org.jboss.as.mail.extension] (MSC service thread 1-2) JBAS015400: Bound mail session [java:jboss/mail/Default]
01:47:23,290 DEBUG [org.apache.catalina.core.AprLifecycleListener] (MSC service thread 1-1) Loaded: crypto
01:47:23,291 DEBUG [org.apache.catalina.core.AprLifecycleListener] (MSC service thread 1-1) Loaded: ssl
01:47:23,292 DEBUG [org.apache.catalina.core.AprLifecycleListener] (MSC service thread 1-1) Loaded: tcnative-1
... 생략 ...
⑦ Context Root 변경
JBoss EAP 6는 기본으로 Context 루트에 ROOT.war 애플리케이션이 배포되어 있습니다. 이 때문에 JBoss EAP 6를 시작하고, http://localhost:8080/에 접근하면 기본 ROOT 애플리케이션이 화면이 보입니다.
운영 환경에서 새로운 웹 애플리케이션을 배포할 때 기존 컨텍스트 루트를 변경하는 것이 일반적입니다. 컨텍스트 루트를 변경하지 않는 경우에도 이 ROOT.war를 활성화한 채 운영하는 것은 보안 측면에서도 바람직하지 않습니다.
- 기본 컨텍스트 루트 변경
ROOT.war는 웹 서브시스템의 가상 서버 설정인 virtual-server 자원으로 설정되어 있습니다. 아래와 같이 enable-welcome-root 속성을 false로 하여 ROOT.war를 비활성화 하는 것이 가능합니다.
[standalone@localhost:9999 /] cd /subsystem=web/virtual-server=default-host
[standalone@localhost:9999 virtual-server=default-host] :write-attribute(name=enable-welcome-root,value=false)
{
"outcome" => "success",
"response-headers" => {
"operation-requires-reload" => true,
"process-state" => "reload-required"
}
}
reload 오퍼레이션을 실행합니다.
[standalone@localhost:9999 virtual-server=default-host] /:reload
{ "outcome" => "success" }※ 티폴트 컨텍스트 루트를 비활성화하지 않고 컨텍스트 루트가 설정된 애플리케이션을 배포하는 경우 배포 오류가 발생합니다.
(5) 데이터소스 서브시스템
성능을 최대화하려고 할 때 데이터베이스 커넥션 풀과 스레드 풀 튜닝은 가장 중요한 영역들입니다. 특히 시스템 리소스 관점에서 보면 데이터베이스 커넥션에 대한 연결은 매우 비용이 많이 드는 작업입니다.
데이터베이스 커넥션 풀링 기능은 웹 애플리케이션 서버 시작 시, 미리 데이터베이스와의 연결을 맺어 풀에 두었다가 다시 사용하는 기술입니다.
Java 애플리케이션에서 데이터베이스를 사용하는 방법은 데이터베이스에 연결한 다음 SQL 문을 실행하여 데이터를 가져와 처리하고, 마지막으로 데이터베이스를 닫는것입니다. 이때 데이터베이스 연결을 맺고 끊는 작ㅇ버은 매우 작업 시간이 오래 걸리는 작업입니다. 요청이 있을 때마다 이러한 단계를 거치는 것은 매우 비효율적이고 데이터베이스와 연결하는 부분에서 병목이 될 가능성이 높습니다. 이것을 방지하기 위해 커넥션 풀링을 사용합니다.
애플리케이션 개발 시 데이터베이스 조회 시 매번 새로운 연결을 생성하고, 바로 닫는 애플리케이션을 개발하는 경우도 있습니다. 이러한 방식은 트랜잭션 처리에 큰 오버헤드가 발생하여 성능이 느려지는 원인이 됩니다.
데이터소스는 DB와의 연결을 미리 생성해 커넥션 풀에 보관합니다. 이 커넥션 풀에 의해 매번 요청마다 DB 연결을 맺고 끊는 시간이 줄어듭니다.
연결 풀은 애플리케이션 스레드에서 connection 요청 시 (javax.sql.DataSource#getConnection)에 풀 안의 사용하지 않는 커넥션을 주고, 사용한 후에 커넥션 풀에 반환합니다.
데이터소스 튜닝 시에는 주로 연결 풀에 대한 다음 사항들을 검토해야 합니다.
- 최대 커넥션 수 설정
- DB 커넥션에 대한 유효성 점검
- 타임아웃 설정
- 스테이트먼트 설정
다음에서는 위이 항목에 대해 튜닝 시 컴토해야 할 주요 파라미터에 대해 설명합니다.
① JDBC 연결 풀 설정 시 주의점
- 커넥션 수가 증가하지 않도록 데이터베이스 커넥션 수를 지정합니다. 'min-pool-size'와 'max-pool-size'를 같게 설정합니다.
- 즉, 운영 시 [최초 커넥션 풀 수] = [최대 커넥션 풀 수]로 합니다.
- 성능 테스트를 하여 부하가 많을 때 최대 커넥션 수를 확인합니다. 커넥션 풀 수는 동적으로 증가, 감소할 수 있지만, 부하가 많이 걸리는 작업이므로 서버 오버헤드를 일으킬 수 있습니다. JBoss 시작 시 데이터베이스 커넥션 수를 최대 커넥션 수로([최초 커넥션 풀 수] = [최초 커넥션 풀 수]) 하는 것을 권장합니다. 연결을 맺어 놓아 시간은 다소 걸리지만 운영 중 연결 생성, 소멸의 오버헤드를 줄일 수 있습니다.
- 스레드 풀의 크기는 DB 커넥션 풀의 'max-pool-size'보다 크거나 최소한 같게 설정합니다.
- 만약 '스레드 수 = 최대 커넥션 수' 일 때 스레드가 각각 하나의 커넥션을 사용한다고 가정하면 부하가 많은 상황에서는 스레드가 최대 연결 즉, 모든 커넥션을 사용한다고 할 수 있습니다. 만약 '스레드 수 < 최대 커넥션 수'라면 스레드가 부족하여 커넥션 풀에 남게 되어, 커넥션을 낭비합니다. 그런데 애플리케이션의 종류에 따라 DB 연결을 하지 않는 작업이 많다면 '스레드 수 > 최대 커넥션 수'로 하는 것이 낭비를 줄일 수 있는 설정입니다.
- 커넥션을 비활성화(inactive)하려면'idle-timeout-minutes'을 설정합니다.
- 커넥션 누수에 대한 트랙킹(track-statements) 옵션은 커넥션 풀에서 close 안한 커넥션을 로그에 남기고 연결을 닫아줍니다. 운영 서버에서는 이 옵션을 사용하지 않는 것을 권장합니다. 이 옵션은 일반적으로 커넥션 풀의 동작을 약간 느리게 합니다.
- 데이터베이스 커넥션 테스트는 이로 인한 부하를 허용하는 경우에만 'check-valid-connection-sql'을 사용합니다.
- 'check-valid-connection-sql'에 실제 사용하는 테이블을 지정하지 않습니다. 더미 테이블(예, 오라클의 경우 dual)를 사용합니다.
- 가능한 경우 'check-valid-connection-sql'보다는 'valid-connection-checker-class-name'을 사용합니다. 쿼리가 아닌 JDBC 내부 API를 사용하기 때문에 속도가 더 빠릅니다.
- prepared나 callable statements의 성능을 개선하고자 할 때는 'prepared-statements-cache-size'를 사용합니다.
- 오라클 JDBC 드라이버 버전이 10g 이하일 경우에는 오라클 XA 데이터소스를 사용할 때 반ㄴ드시 'no-tx-separate-pools' 옵션을 설정합니다. 오라클 XA 드라이버에서 XA 연결 시 글로벌, 로컬, NO-트랜잭션을 혼용해서 사용할 경우 별도 커넥션이 맺어집니다.
- JBoss의 경우 커넥션 풀이 생성될 때 min-pool-size에 지정된 연결이 맺어지지 않습니다. 애플리케이션이 맨 처음 사용할 때 연결을 맺습니다. 애플리케이션 실행 성능을 높이려며 ㄴprefill 속성을 true로 설정하여 커넥션 풀이 생성될 때 min-pool-size의 연결이 맺어지도록 설정하는 것이 좋습니다.
<스레드 수와 최대 커넥션 풀 수의 관계>
운영 시 일반적인 설정 기준은 [최초 커넥션 풀 수] = [최대 커넥션 풀 수] = 스레드 ± a로 하는 것이 좋습니다. 부하 테스트를 통해 시스템에 가장 적합한 설정을 찾아야 합니다.
min-pool-size = max-pool-size = threads ± a
② 커넥션 풀 수 설정
연결 풀은 기본적으로 '데이터베이스와 커넥션을 미리 맺어 두고 필요할 때 재사용'이라는 전략으로 데이터베이스 연결의 속도를 고속화해 성능을 향상하는 방법으로 datasources 서브시스템의 자원으로 관리합니다.
또 데이터소스에 대해 Non-XA 및 XA 데이터소스 두 가지 방식이 있습니다.
- Non-XA 데이터소스의 경우
/subsystem=datasources/data-source=<데이터소스명>
- XA 데이터소스의 경우
/subsystem=datasources/xa-data-source=<데이터소스명>
③ 커넥션 풀의 타임아웃 설정
커넥션 풀의 동작 방법을 살펴보면 작업이 필요한 경우 애플리케이션 스레드는 커넥션 플로부터 커넥션을 얻습니다. 이때, 커넥션 풀이 가능한 연결 개수의최대값에 도달하여 사용 가능한 커넥션이 없는 상태라면 다른 애플리케이션 스레드가 사용하고 있는 커넥션이 반환되고 사용 가능한 커넥션이 풀에 확보될 때까지 기다리게 됩니다.
이때 얼마나 기다리고 있을지 타임아웃을 설정할 수 있습니다. 이외의 다양한 타임아웃 설정은 아래와 같습니다.
| 속성명 | 기본값 | 설명 |
| blocking-timeout-wait-millis | 30000 | 연결 대기로 블록되는 최대 시간을 밀리 세컨트로 지정 연결의 대기 사긴이 설정 시간을 초과했을 경우, javax.resource.ResourceException이 발생 ※ 설정 파일(XML)의 파리미터명은 blocking-timeout-millis |
| idle-timeout-minutes | 30 | 풀에서 커넥션이 Idle 상태로 남아있는 시간을 분 단위로 지정 연결이 마지막 사용되고 지정된 시간 동안 사용되지 않으면 연결은 폐기 0을 설정하면 Idle 상태의 커넥션은 폐기되지 않음 Idle 상태인 커넥션 체크는 설정 값의 1/2의 간격으로 실행 |
| set-tx-query-timeout | false | JDBC의 쿼리 타임아웃에 트랜잭션 타임아웃 시간을 설정할 것인지 true, false로 지정 트랜잭션 타임아웃이 발생했을 경우, 트랜잭션 타임아웃 발생 시점에 실행 중인 쿼리는 중단 |
| query-timeout | - | JDBC 쿼리 타임아웃을 초 단위로 지정 쿼리 실행 전에 java.sql.Statement@setQueryTimeout를 사용해 타임아웃을 적용 기본값은 타임아웃을 적용하지 않음 |
| allocation-retry | 0 | 연결을 얻지 못할 때 재시도 횟수를 지정 기본값은 처음 연결을 얻지 못하면 에러가 발생(Throw함) |
| allocation-retry-wait-millis | 5000 | 연결을 얻지 못하여 재시도할 때, 실행 간격을 밀리 세컨드로 지정 |
(6) PreparedStatement 튜닝
PreparedStatement는 그 이름대로 JDBC 문(SQL 문장)을 캐시하여 성능을 향상하는 기능입니다. 다음은 일반 Statement를 이요한 소스와 PreparedStatement를 이용한 소스의 예제입니다.
- Statement를 이용한 JDBC 연결
Statement stmt = conn.createStatement();
for ( int ID = 0 ; id < 10000 ; id++) {
String SQL = "SELECT NAME FROM ITEM WHERE I_ID =" + id;
ResultSet rs = stmt.executeQuery( sql );
while ( rs.next() ) {
// 테이블의 내용 처리
}
}
- PreparedStatement를 이용하 JDBC 연결
String SQL = "SELECT NAME FROM ITEM WHERE I_ID =?";
PreparedStatement PS = conn.prepareStatement ( sql );
for ( int ID = 0; id < 10000 ; id++ ) {
ps.setInt( 1 , id );
ResultSet rs = ps.executeQuery();
while ( rs.next(0 ) {
// 테이블의 내용 처리
}
}
Statment는 실행했을 때마다 서버에서 SQL문을 분석해야 하는 반명, PreparedStatement는 미리 컴파일되기 때문에 쿼리의 수행 속도가 Statement에 비해 빠르고 또한 한 번만 분석되면 재사용이 됩니다.
Statement와 비교할 때 PreparedStatement가 유리한 경우는 동일한 쿼리에 대해서 특정 값만 바꾸어서 여러 번 실행할 때, 많은 데이터를 조작하여 쿼리문이 복잡할 경우, 파리머타가 많을 경우입니다.
위의 예제를 실제 실행해 보면, PreparedStatement를 사용하는 것이 성능이 월등히 빠릅니다.
실제 웹 애플리케이션에서는 PreparedStatement 자체로 성능 향상이 있기는 하겠지만, 이 부분도 전체 성능 중에 일부분이기 때문에 현실과는 차이가 있습니다.
위의 예제 프로그램의 경우 한 번 SQL문을 준비한 후, 같은 PreparedStatement를 10,000번 반복 실행하도록 작성되었습니다. 현실에서는 개발자가 웹 애플리케이션을 개발할 때 위의 예제처럼 한 번 SQL문을 준비한 후 PreparedStatement를 10,000번 실행하고, Close하는 경우는 없습니다. 즉, JSP와 서블릿이 호출될 때마다 PreparedStatement를 만들고 실행한 후 닫아버리기 때문입니다.
① 애플리케이션 서버의 PreparedStatement 캐싱 기능
대부분 애플리케이션 서버는 'PreparedStatement 캐시'라는 기능을 제공하고 있습니다. PreparedStatement 캐시는 한 번 생성된 PreparedStatement를 버리지 않고 애플리케이션 서버의 메모리에 캐시합니다. 같은 SQL 실행 요청일 경우 캐시에서 PreparedStatement를 불러와 다시 사용합니다. 즉, SQL 문자 해석 작업을 다시 수행하지 않게 됩니다. 일반 웹 애플리케이션의 경우, 같은 SQL이 여러 번 사용되는 경우가 많아서 이를 통해 성능 향상을 기대할 수 있습니다.
② PreparedStatement 캐시의 효과
- Java 객체 생성 비용 절감
객체 생성으 비용은 의외로 높습니다. 캐시를 이용하여 객체 생성 횟수를 줄일 수 있습니다. 또한, 마찬가지로 삭제된 객체 수가 줄어들게 되어 JVM 가비지 컬렉션이 줄어드는 장점도 있습니다. 애플리케이션 서버의 CPU 사용률을 줄일 수 있습니다.
- 데이터베이스와 통신 횟수 감소
PreparedStatement 사용 시 SQL문 해석을 위해 데이터베이스에 요청을 보내게 되지만, 캐시된 PreparedStatement를 사용하게 되면 그 만큼 통신 횟수가 줄어들게 됩니다. 그러면 애플리케이션 서버, 데이터베이스 서버의 CPU 사용률 및 네트워크 사용률을 줄일 수 있습니다.
- 데이터베이스에서 Parse 횟수 감소
PreparedStatement 사용 시 데이터베이스에서 쿼리 파싱과 쿼리 플랜을 만듧니다. 캐시를 사용하게 되면 파싱된 SQL 분석문을 버리지 않기 때문에 다시 사용할 대 파싱은 다시 실행되지 않습니다. 이렇게 데이터베이스 서버의 CPU 사용률을 줄일 수 있습니다.

③ Statement 설정
Statement에 관한 데이터소스 자원의 주요 속성은 아래 표와 같습니다. Non-XA 및 XA에서 모두 사용할 수 있습니다.
| 속성명 | 기본값 | 설명 |
| track-statements | nowarn | 연결이 풀에 반환되었을 때 닫히지 않은 java.sql.PreparedStatement나 java.sql.ResultSet을 어떻게 트랙킹할지를 다음 값으로 지정 - true : PreparedStatement 또는 ResultSet가 닫히지 않은 경우에 경고 메시지가 출력 - false : 트래킹을 하지 않음 - nowarn : 트랙킹은 하지만, 경고 메시지는 출려되지 않음(기본값) |
| prepared-statements-cache-size | - | 연결마다 캐시되는 PreparedStatement 개수를 지정 ※ 설정 파일(XML)의 파라미터명은 prepared-statement-cache-size |
- Statement 설정 튜닝
PreparedStatement를 사용하면 JDBC 연결의 성능을 향상하는 것은 잘 알려져있습니다. 몇몇 웹 애플리케이션 서버는 'PreparedStatement 캐시'라는 기능을 가지고 있으며 이를 통해 성능을 향상할 수 있습니다.
prepared-statements-cache-size에 1 이상의 정수를 지정하여 데이터베이스 접속마다 Statement가 캐시됩니다. 일반적으로 애플리케이션에서 사용하는 SQL (java.sql.PreparedStatement를 사용하는 것)의 수를 지정합니다. SQL 문의 종류가 많을 경우, DBMS의 로그 등을 분석하여 캐시 사이즈를 설정합니다.
- CLI를 사용한 커넥션 풀 속성 변경
CLI에서 postgresDS라는 풀에 대해서 min-pool-size, max-pool-size, pool-prefill을 설정하는 방법은 아래와 같습니다.
postgresDS의 풀의 min-pool-szie와 max-pool-size를 각각 '40', pool-frefill을 'true'로 설정
[standalone@localhost:9999 /] cd subsystem=datasources/xa-data-source=postgresDS
[standalone@localhost:9999 xa-data-source=postgresDS] :write-attribute(name=min-pool-size, value=40)
{ "outcome" => "success" }
[standalone@localhost:9999 xa-data-source=postgresDS] :write-attribute(name=max-pool-size, value=40)
{ "outcome" => "success" }
[standalone@localhost:9999 xa-data-source=postgresDS] :write-attribute(name=pool-prefill, value=true)
{
"outcome" => "success",
"response-headers" => {
"operation-requires-reload" => true,
"process-state" => "reload-required"
}
}
[standalone@localhost:9999 xa-data-source=postgresDS] /:reload
CLI에서 postgresDS라는 풀에 대한 설정 확인은 아래와 같이 수행합니다.
[standalone@localhost:9999 /] cd subsystem=datasources/xa-data-source=postgresDS
[standalone@localhost:9999 xa-data-source=postgresDS] :read-attribute(name=min-pool-size)
{
"outcome" => "success",
"result" => 40
}
[standalone@localhost:9999 xa-data-source=postgresDS] :read-attribute(name=max-pool-size)
{
"outcome" => "success",
"result" => 40
}
[standalone@localhost:9999 xa-data-source=postgresDS] :read-attribute(name=prefill)
{
"outcome" => "success",
"result" => true
}
(7) 서브시스템의 추가/삭제
서브시스템에서 설명한 것처럼 JBoss EAP 6에서는 이용하지 않는 서브시스템을 삭제할 수 있습니다.
어느 서브시스템을 남기고 어느 서브시스템을 삭제할지는 JBoss EAP 6상에서 동작하는 애플리케이션이나 시스템에 따라 달라서 한 마디로는 말할 수 없지만, 운영 환경에서 반드시 삭제해야 하는 서브시스템이 있습니다.
① H2 Database의 삭제
H2 Database는 운영 환경에서 사용하는 것이 지원되지 않습니다. 기본값인 H2 Database를 사용한 데이터소스 ExampleDS로 정의되어 있기 때문에 이를 삭제합니다.
[standalone@localhost:9999 /] /subsystem=datsources/data-source=ExampleDS:remove
② Deployment Scanner 삭제
[standalone@localhost:9999 /] /subsystem=deployment-scanner/scanner=default:remove
(8) 로깅
애플리케이션 생명 주기를 보면 개발 단계와 테스트 단계에서 개발자는 로깅을 최대한으로 활용합니다. 그러나 운영 환경에서는 로깅이 병목이 될 수도 있습니다. 로깅으로 인해 성능에 영향을 주지 않고 유익한 정보를 제공해 주기를 원할 것입니다.
애플리케이션을 운영하기 위해서 아래의 내용을 확인합니다.
- 운영 환경에서는 콘솔 로깅은 사용하지 않습니다.
모든 로그를 볼 수가 있도록 JBoss EAP의 기본적인 구성에서는 콘솔 로깅이 활성화되어 있습니다. 운영 환경에서 이것은 I/O를 소비를 많이하는 프로세스입니다. 대용량 처리 애플리케이션에서 콘솔 로깅을 끄는 것만 으로도 성능 향상 이득을 얻을 수 있습니다.
- Verbose 모드를 사용하지 않습니다.
로그가 적으면 적을수록 I/O는 발생하지 않기 때문에 애플리케이션 성능도 향상됩니다. 로깅은 항상 성능과 트레이드 오프입니다. 운영 환경에서는 실제로 얼마나 로깅이 필요한지 주의해서 생각해야 합니다.
- 비동기 로깅을 활용합니다.
대용량 처리를 하는 애플리케이션에서는 비동기 로깅을 사용하는 것만으로도 큰 차이가 생깁니다. 비동기 로깅은 로그 메시지르르 큐에 보내고 애플리케이션은 마치 로깅이 완료된 것으로 처리하고 제어권을 반환합니다. 해당 로그 메시지는 다른 스레드가 큐에서 가져와 로그 처리를 합니다.
- 디버그용 로그 문장을 If(debugEnabled())로 작성합니다.
애플리케이션이 많은 양의 디버그 코드를 포함하고 있으면, if 문으로 디버그 로그를 남겨야 성능이 빠릅니다. 이 조건문이 없으면 애플리케이션은 각각의 로그 문장을 모두 String 오브젝트로 생성하고 Log4j는 각각의 로그메시지를 LoggingEvent 오브젝트로 변환합니다. 로그 레벨은 오브젝트가 생성된 다음에 체크되기 때문에, 로그 레벨 설정과 관계 없이 객체가 생성되고 로그 이벤트가 발생합니다. 때에 따라 이것은 무수히 많은 일시적인 String 오브젝트와 LoggingEvent 오브젝트들이 생성되기 때문에 그 결과 메모리와 가비지 컬렉션 문제가 발생하게 되어 성능이 대폭 감소하게 됩니다. 디버그 로그 코드를 조건절에서 코딩하면 불필요한 로그 처리가 발생하지 않아 성능에 영향을 미치지 않습니다.
| 6. 관련 시스템 튜닝 |
성능의 80%는 애플리케이션 설계 시 결정되지만, 단순한 실수로 성능의 문제가 발생하는 경우도 있습니다. 문제가 발생하였을 때 논리적으로 어느 부분이 병목인지 조사해 볼 수 있는 몇가지 예를 살펴봅시다.
(1) 웹 서버 튜닝
예를 들어 Apache 경우 대량의 접근이 급격하게 집중했을 경우, 많은 부하를 안정적으로 처리하기 위해 다음 파라미터를 조정합니다.
- StartServers
- MaxClients
- MaxSpareServers / MinSpareServers
① 사이즈가 큰 파일로 인한 웹 서버 성능 감소
- 현상
HTTP 서버의 큰 역할은 웹 브라우저에서 요청한 정적 파일을 브라우저로 다시 전송하는 것입니다. 즉, 크기가 큰 이미지 파일이 많이 포함된 페이지가 많은 경우 자주 다운로드하기 때문에 웹 서버의 부하가 높습니다. HTTP 서버의 부하가 높아지면 당연히 Java 애플리케이션 서버로 중계하는 통신 프로세스가 느려져 전체적으로 성능이 감소할 수 있습니다.
- 조치
웹 서버의 하드웨어 성능 향상을 하는 것이 해결 방법입니다. 즉 하드웨어 CPU 수, 메모리 등을 업그레이드 합니다. 또는 로드 밸선서(L4) 등을 통하여 웹 서버 시스템을 Scale-Out합니다.
② SSL 사용으로 인한 성능 감소
- 현상
SSL을 사용하는 페이지가 많은 경우 성능이 감소될 수 있습니다. SSL을 사용하면 약 CPU를 30% 정도 추가 요구됩니다.
- 조치
하드웨어 업그레이드나 웹 서버에 대한 Scale-Out을 통한 해결 방법이 있습니다. SSL로 인해 성능 문제가 되는 경우 SSL을 사용하는 페이지 개수를 줄이는 것도 튜닝 방법의 하나입니다.
(2) 데이터베이스 튜닝
데이터베이스 성능 튜닝은 애플리케이션 서버와 관련성이 없습니다. 일반적인 데이터베이스 튜닝 작업을 진행합니다.
① 애플리케이션 서버 튜닝
애플리케이션 서버의 성능 문제 원인을 찾는 것은 어렵습니다. 사실, 문제의 원인을 찾는 것은 그렇게 단순하지 않고 개발한 코드가 성능을 감소시키는 원잉일 경우가 많습니다. 이것을 어떻게 찾아가면 좋을까요?
- 웹 시스템의 계층별 부하 상황 파악
HTTP 서버, 애플리케이션 서버, 데이터베이스 서버의 부하 데이터를 얻습니다. 부하 테스트 도구를 이용하면 좋을 것입니다. 만약 하나의 서버만 과부하 상태라면 위에서 설명한 것과 같은 항목을 의심하고 원인을 조사합니다.
- 구간별 네트워크 부하 데이터를 파악
인터넷, HTTP 서버, 애플리케이션 서버, 데이터베이스 서버 사이의 네트워크 부하 상태를 확인합니다. 먼저 HTTP 서버를 시스템에서 분리하여 테스트합니다.
일반적인 방법으로 웹 서버에 걸리는 부하를 애플리케이션 서버에 직접 걸어 테스트하여도 여전히 성능이 나오지 않는 경우엔 애플리케이션 서버 내에서 더 자세히 확인해야 합니다.
<부하 상황에서 애플리케이션 서버의 CPU 사용률이 늘지 않는 경우>
부하 테스트 도구를 사용해도 애플리케이션 서버의 CPU 사용률이 오르지 않으면 어떤 리소스에 락이 걸려 그 락이 풀리기를 기다리고 있을 수 있습니다. 일반적인 원인으로 생각되는 것들은 다음과 같습니다.
- 커넥션 풀의 대기 : 우선 생각할 수 있는 것은 SQL 처리에 시간이 걸리는 경우입니다. 커넥션 풀 수가 부족해서 여러 스레드가 데이터베이스 연결을 얻기 위해 대기합니다.
- 동기화 객체 사용 : 동기화(synchronized)를 정의하는 클래스를 구현하는 경우에 발생합니다. 특히 synchronized가 선언된 클래스나 메소드의 처리가 느린 경우 리소스가 해제될 때까지 다른 스레드가 기다리게 됩니다.
- 스레드 데드락 : 애플리케이션 서버 내에서 사용자 프로그램이 스레드를 생성하여 동기화 하는 경우는 많지 않습니다. 스레드를 사용할 때는 많은 주의가 필요합니다. 스레드 데드락은 스레드 덤프를 출력하면 표시됩니다.
위 같은 경우는 부하가 높은 상태에서 교착 상태(여러 스레드가 서로 대기하고, 락이 걸리는 현상. Dead Lock)가 되기 쉽습니다. 다라서 성능 감소와 함께 교착 상태에 빠져 있지 않은지도 확인하는 것이 좋습니다.
참고서적 : 거침없이 배우는 JBoss
'IT 이야기 > JBoss EAP' 카테고리의 다른 글
| [JBoss EAP] 버전별 AJP 프로토콜의 Max Connecction 개수 설정 (0) | 2021.06.14 |
|---|---|
| JBoss EAP 6과 친해지기 24탄 - JBoss EAP 6 운영환경 구축 가이드 (4) | 2021.01.29 |
| JBoss EAP 6과 친해지기 23탄 - JBoss EAP 6 튜닝 #1 (0) | 2021.01.18 |
| JBoss EAP 6과 친해지기 22탄 - JBoss EAP 6 모니터링 #2 (0) | 2021.01.11 |
| JBoss EAP 6과 친해지기 22탄 - JBoss EAP 6 모니터링 #1 (0) | 2021.01.11 |




댓글